
728x90
- DB
- Index
Index 란?Index 작동 원리- Index 종류
- B-Tree 인덱스
- Hash Indexes
- Bitmap Index
- GIST(Generalized Search Tree)
- R-Tree
- Full Text Index
- Spatial Index
- Trie(Prefix Tree) Index
- Covering Index
- 영속성
- 트랜잭션
- ORM
- ACID
- N+1 문제
- DB 정규화
- Data Replication
- sharding 전략
- CAP 이론
- Index
B-Tree 인덱스

그 전에... B-Tree 란? 이런거다 라는걸 알고 가야함.
B-Tree 자료구조란?
- 데이터베이스 및 파일 시스템에서 인덱싱을 위해 널리 사용되는 자료구조
- 데이터 삽입, 삭제, 검색 등의 작업을 지원하기 위해 설계됨.
특징
- 균형 유지
B-Tree 는 자동으로 균형을 유지하는 트리구조. 모든 리프 노드(트리의 가장 하단에 위치하는 노드) 는 루트에서 동일한 거리에 있음.
이러한 특징 때문에 균일한 검색 시간을 보장함. - 분할 및 병합
노드의 데이터가 가득 차거나 비워질 때 자동으로 노드를 분할하거나 병합함. ➡️ 트리의 균형을 유지하는데 도움을 줌. - 노드는 최대 M개의 자식 노드를 가질 수 있다.
각 노드는 일반적인 이진 트리보다 더 많은 수의 자식을 가질 수 있음. 데이터의 효율적인 저장과 접근을 가능하게 함.
구조
- 노드
B-Tree 의 기본 단위, 여러 개의 Key 와 자식 노드에 대한 포인터를 포함. 특정한 최소 및 최대 키 수를 유지함. - root node : 최상단 노드
leaf node : 자식이 없는, 최하단의 노드
internal node : root와 leaf 노드를 제외한 모든 노드 - 키
노드 내에 저장된 데이터 요소. 각 키는 노드를 정렬된 순서로 유지하는데 사용됨. - 자식 노드 포인터
각 키는 두 개의 자식을 가리키는 포인터를 가짐. 하나는 키보다 작은 값을 갖는 서브트리, 다른 하나는 키보다 큰 값을 찾는 서브트리를 가짐.
연산
- 검색
데이터를 검색하는 과정은 루트 노드에서 시작하여 해당 키 값을 포함하는 리프 노드를 찾을 때까지 내려가는 방식으로 진행됨. - 1) 노드의 값보다 검색값이 작으면 왼쪽 자식으로 이동
2) 노드의 값보다 검색값이 크면 오른쪽 자식으로 이동
3) 이를 반복하며 검색값을 가진 노드를 발견시 종료 - 삽입
새로운 키가 삽입되면 적절한 위치를 찾아서 그 위치에 키를 추가함.
노드가 가득 차면, 중간값을 기준으로 노드를 분할하여 내려가는 방식으로 진행됨.
1) 루트 노드에서 시작해 삽입하려는 값과 노드의 값을 비교함.
2) 삽입하려는 값이 노드의 값보다 작으면 왼쪽 자식으로 이동
3) 삽입하려는 값이 노드의 값보다 크면, 오른쪽 자식으로 이동
- 삭제
키를 삭제할 때는 해당 키를 찾아서 제거하고, 필요하면 노드를 병합하거나 재배열하여 트리의 균형을 유지함.
그러면 B-Tree Index는?
B-Tree 인덱스
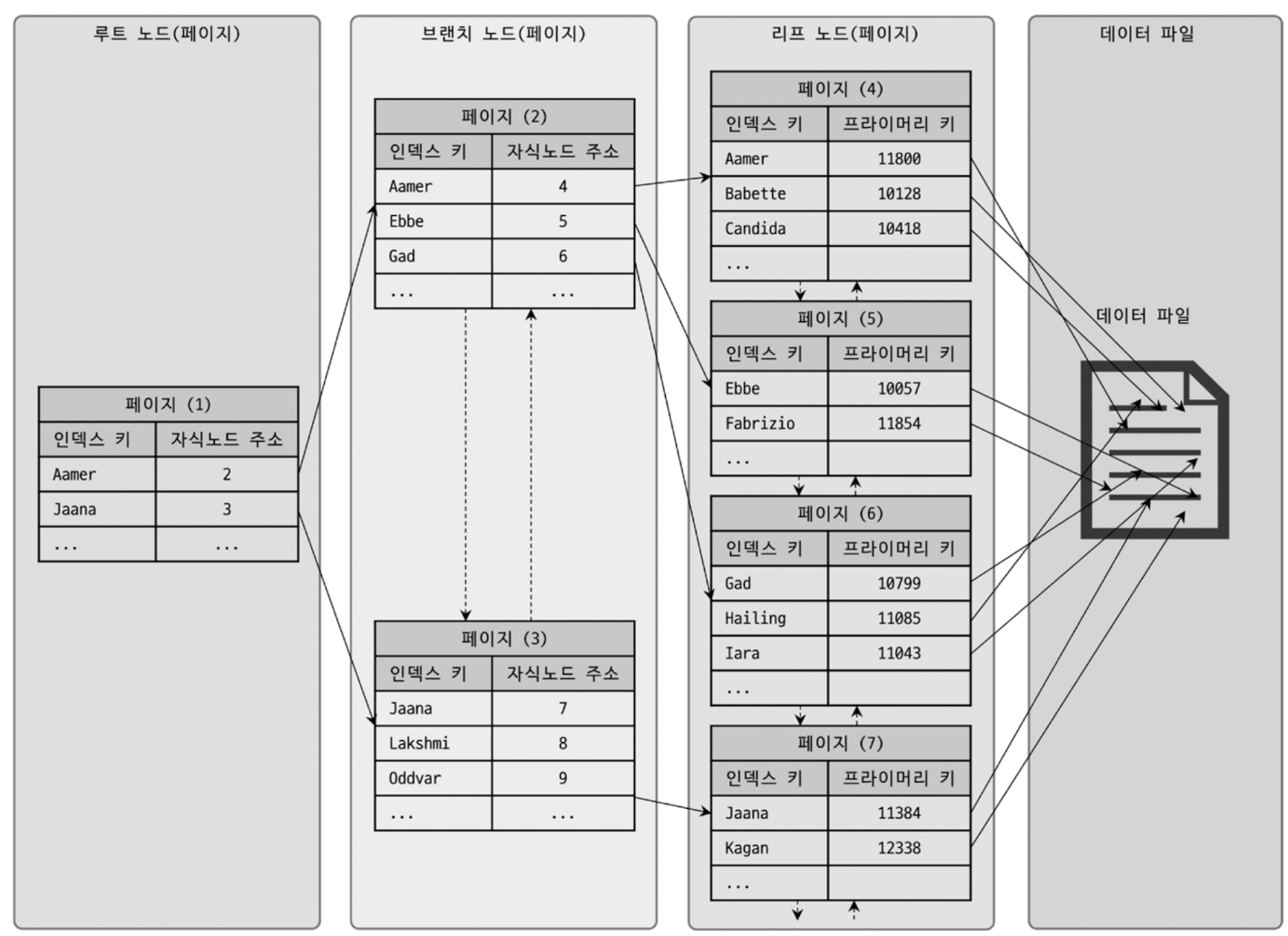
- MySQL 에서 B-Tree 인덱스는 가장 일반적으로 사용되는 인덱스 유형 중 하나
- 다양한 데이터 타입에 걸쳐 광범위하게 활용되며, 빠른 데이터 검색, 삽입, 삭제 등을 가능하게 해주는 효율적인 자료 구조를 기반으로 함.
특징
- 멀티-레벨 인덱스
MySQL 의 B-Tree 인덱스는 여러 레벨의 노드로 구성되어 있음. - 최상위에는 루트 노드가 있고, 가장 하위에는 리프 노드가 있으며, 중간에는 내부 노드가 위치함.
- 정렬된 데이터
B-Tree 인덱스는 데이터를 키의 정렬된 순서로 저장함. 이 정렬은 범위 쿼리 (BETWEEN,>,<등)와 정렬된 결과를 필요로 하는 쿼리에 효율적임. - 키 액세스 최적화
인덱스 키를 통해 데이터에 접근하면 전체 테이블 스캔을 피하고 필요한 데이터를 더 빠르게 찾을 수 있음.
작동 방식
- 검색 : key 를 사용해서 데이터를 검색할 때, B-Tree 구조를 따라 적절한 노드로 내려가며 검색 범위를 좁혀나감.
O(log n)를 가짐. - 삽입 : 새로운 데이터가 테이블에 추가될 때, 해당 키 값에 맞는 위치를 B-Tree 에서 찾아 데이터를 삽입함. 필요하다면 노드 분할을 통해 균형을 유지함.
- 삭제 : 키 값에 해당하는 데이터를 삭제할 때는 해당 노드에서 데이터를 제거하고, 필요에 따라 노드를 병합하거나 재배열하여 트리의 구조적 균형을 유지함.
사용 방법
- 인덱스 생성
CREATE INDEX index_name ON table_name (colum_name);- 복합 인덱스
- 여러 컬럼을 조합하여 인덱스를 생성할 수 있으며, 이 경우 쿼리의 WHERE 절에 여러 컬럼이 사용될 때 효과적
CREATE INDEX index_name ON table_name(column1, column2);- 인덱스 사용 확인
EXPLAIN명령어를 사용하여 쿼리가 인덱스를 사용하는지 확인할 수 있음.
EXPLAIN SELECT * FROM table_name WHERE column_name = 'value';728x90
'99클럽 TIL' 카테고리의 다른 글
| 99클럽 코테 스터디 6일차 TIL DB Bitmap Index (0) | 2024.05.25 |
|---|---|
| 99클럽 코테 스터디 5일차 TIL DB Hash Indexes (0) | 2024.05.24 |
| 99클럽 코테 스터디 3일차 TIL DB Index 작동 원리 (0) | 2024.05.22 |
| 99클럽 코테 스터디 2일차 TIL DB Index (0) | 2024.05.21 |
| 99클럽 코테 스터디 1일차 TIL JAVA 17 (0) | 2024.05.20 |
Comment