Fluentd란?
최근 회사에서 로그수집에 대해 이야기가 나왔던 적이 있었다. 현재 로그파일이 서버에 있고 폴더 별로 나누어져 있기에 로그를 확인하려고 하면 어떤 Controller에서 어떤 Method를 사용했는지 파악 한 후에 폴더를 찾아가는 형식 이였다. 그래서 생각한게 fluentd를 적용해 보는 것이였다. 통합적으로 서버의 로그를 모아서 필요할 때 검색하여 찾아보는 것을 목표로 하였고 마침 fluentd 와 azuresotrage를 이용하여 로그를 저장, 확인하려고 했다. 이 글은 Fluentd가 무엇인지 어떤 기능이 있는지 적용전에 확인하기 위해서 적는 글이다.
Fluentd 란?
오픈 소스 데이터 수집기, C와 Ruby 기반으로 만들어졌다. 흔히 로그를 수집할 때 많이 사용한다.

이미지 출처 : https://www.fluentd.org/architecture
fluentd 가 나오기 전까지 각각의 로그마다 db나 sotrage 등에 넣었지만 fluentd 가 나온 후에는 적절하게 분리된 것을 볼 수 있다.
이렇게 fluentd 가 통합하여 사용할 수 있는 이유는 fluentd가 JSON 데이터로 구조화 하려고 하기 때문이다.
JSON을 사용한 통합 로깅

이미지 출처 : https://www.fluentd.org/architecture
이렇게 데이터를 구조화 하면 여러 소스 및 대상의 로그를 통합할 수 있다.
What is Fluentd? | Fluentd
Fluentd History Fluentd was conceived by Sadayuki "Sada" Furuhashi in 2011. Sada is a co-founder of Treasure Data, Inc., a primary sponsor of the Fluentd project. Since being open-sourced in October 2011, the Fluentd project has grown dramatically: dozens
www.fluentd.org
통합한 로그를 어떻게 처리할까?
fluentd의 내부에서의 흐름

tag, time, record로 이루어진 event가 buffer에 쌓이고 Output에 가서 전송
Pluggable Architecture

통합한 로그들을 다른 Storage나 DB 등에 저장 할 수 있도록 확장성이 넓은 이유는 fluentd 가 플러그형 아키텍쳐를 가지고 있기 때문이다. 이러한 플러그형 아키텍쳐로 인해 수십개의 데이터 소스와 데이터 출력을 연결할 수 있다.
1.Input Plugin
plugin list
- tail
- forward
- udp
- tcp
- unix
- http
- syslog
- exec
- sample
- monitor_agent
- windows_eventlog
Input Plugin의 파라미터들은 안에서 정의된다.
tail
가장 기본적인 플러그인이다.
<source>
@type tail
path /var/log/access_log/access.log
pos_file /var/log/fluent/access_log/access.log.pos
tag tag.access
<parse>
@type none
</parse>
</source>파일을 tail에서 데이터를 읽어들인다. 파일의 시작부터 읽지 않고, 로테이팅 되어 새로운 파일이 생성됬을 때 처음부터 읽는다.
또 해당 파일의 읽던 부분을 추적하기 때문에 pos_file 파라미터를 사용할 경우 fluentd 가 재실행 되었을 때 파일의 마지막에 읽은 부분 부터 다시 처리한다.
Output Plugin
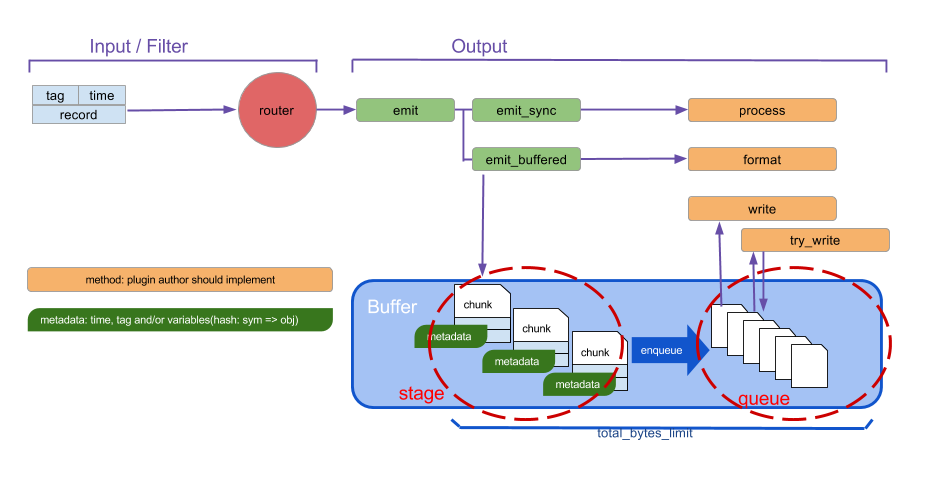
Fluentd v1.0에서는 Output Plugin은 3개의 버퍼링, flushing 모드를 가진다.
1) Non-Buffered
데이터를 버퍼링 하지 않고 결과를 기록하지 않고 즉시 결과를 보낸다.
2) Synchronous Buffered
stage , queue로 버퍼 chunk 파일을 다룬다.
3) Asynchronous Buffered
chunk를 커밋하지 않음.
Output Plugin은 Buffer 플러그인을 가지고 있는데 non-buffered 모드를 사용하는 것 외에는 Buffer 플러그인이 들어간다고 보면된다.
match 태그 안에서 선언되며 source 태그에서 설정한 tag로 pattern 부분에 넣으면 라우팅 되어 source에서 가져온 파일을 출력하게 된다.
<match pattern>
@type file
path /var/log/fluent/myapp
compress gzip
<buffer>
timekey 1d
timekey_use_utc true
timekey_wait 10m
</buffer>
</match>파라미터 list
플러그인에 따라 다양하므로 공식 사이트를 참조
Buffer Plugin
buffer 플러그인은 Input Plugin에서 보낸 event를 chunk 파일로 가지고 있다가 Queue에 담아 flush하는 구역이다.
buffer에 사용 되는 파라미터는 다음과 같다.
flush_mode
default : default
types : default, lazy, interval, immediate
flush_interval
버퍼에서 chunk를 flush하는 사이의 시간
flush_mode가 interval일때만 가능 그 외에는 무시됨.
defautl : 60 (1분)
flush_thread_count
버퍼를 flush할 스레드의 개수
default : 1
스레드가 많으면 많을 수록 서버의 CPU를 잡아먹게 된다.
flush_thread_interval
flush 스레드에서 버퍼 flush 를 확인 하는 사이의 sleep하는 시간(초)
default : 1.0
flush_thread_burst_interval
많은 버퍼 chunk가 queue에 있을 때 flush 사이의 sleep 시간(초)
default : 1.0
overflow_action
queue가 가득차면 buffer의 동작을 제어
types
- throw_exception(default) : BufferOverflowError을 발생. data 스트리밍 방식에 적절하다.
- block : queue에 여유공간이 있을 때 까지 queue를 막음. ( 잘 고려해서 사용)
- drop_oldest_chunk : 가장 오래된 chunk를 삭제. 최신 event 가 오래된 event 보다 중요할 때 사용.
Buffer 에는 flush가 실패 했을 때의 다룰 수 있는 파라미터가 있다.
queue에 남아있다가 Fluentd는 설정한 시간만큼 기다렸다가 재시도 하게된다.
retry_type
버퍼를 flush하기 위해 다음 retry를 기다린다.
types
- exponential_backoff(default) : 지수 backoff, retry_timeout 의 시간 안에 2배씩 증가. 처음 기다리는 시간은 retry_wait의 수치에 따라 달라짐. retry_wait 1인 경우
- 1초 대기 ... 재시도 ... 실패 , 2초 대기 .... 재시도 ... 실패, 4초 대기 ... 재시도 ... 실패 , ...
- periodic
retry_forever
이 파라미터가 true인 경우 계속 flush를 다시 시도.
retry_timeout
플러그인이 buffer의 chunk를 버릴 때 까지 실패하는 동안 flush를 다시 시도하는 최대 시간.
default : 72h( 72시간)
retry_max_times
실패하는 동안 flush를 다시 시도하는 최대 횟수.
retry_wait
플러시를 다시 시도하기 전에 대기할 시간(초), exponential_backoff의 기준이 된다.
위에서 언급하지 않은 parameter 사용법
<match pattern>
@type file
path /var/log/fluent/myapp
compress gzip
<buffer>
timekey 1d
timekey_use_utc true
timekey_wait 10m
</buffer>
</match>Output Plugin에서 사용할 뿐 아니라 다른 plugin에서도 사용할 수 있다.
path를 tag에서 긁어온 파일의 경로로 동적으로 설정하고 싶다.
tag를 그룹화 해서 사용하게되면 tag.A, tag.B로 사용할 수 있다. 이 경우 match 태그에서 사용할 때 pattern 부분에
<match tag.*>이런 식으로 쓸 수 있다. 그러면 match 태그에서 설정한 path에만 넣는게 아니라 source에서 긁어온 파일의 경로로 path를 동적으로 사용할 때
<source>
@type tail
path /var/log/...
tag tag.*
...
</source>이런 식으로 하게 되면 tag.path.var.log. ... 이런식으로 tag가 설정된다.
그 후에 match태그로 돌아가서
<match tag.*>
...
path /result/${tag[4]/...
...
</match>path /result/${tag[4]}/.. 이런식으로 설정해 놓으면 tag의 인덱스값으로 tag의 일정 부분을 가지고 온다.
var를 넣고 싶은 경우 tag.path.var.log. ...에서 우리가 아는 배열의 index 값을 생각해서 path를 index 0으로 시작 var 는 index 2번에 위치하므로 path /result/${tag[2]}/.. 로 설정하면 된다.
환경변수를 설정해서 사용하고 싶다.
설치한 버전에 따라 다른데 내 경우는 /opt/td-agent/usr/sbin/td-agent에 있었다.
sudo vi /opt/td-agent/usr/sbin/td-agent
#!/opt/td-agent/embedded/bin/ruby
ENV["GEM_HOME"]="/opt/td-agent/embedded/lib/ruby/gems/2.4.0/"
ENV["GEM_PATH"]="/opt/td-agent/embedded/lib/ruby/gems/2.4.0/"
ENV["FLUENT_CONF"]="/etc/td-agent/td-agent.conf"
ENV["FLUENT_PLUGIN"]="/etc/td-agent/plugin"
ENV["FLUENT_SOCKET"]="/var/run/td-agent/td-agent.sock"
load "/opt/td-agent/embedded/bin/fluentd"여기에다가 비슷하게 ENV["변수이름"] ="넣고싶은 값" 을 하고 저장한 후에 conf파일에서 사용할 때는
"#{ENV['설정한 변수이름']}"으로 넣으면 된다.
<match "#{ENV['HOSTNAME']}">
@type azurestorage
azure_storage_account
azure_storage_access_key
azure_container platformlogs
azure_storage_type blob
store_as text
auto_create_container true
path qa/happycode/${tag}/
azure_object_key_format %{path}%{time_slice}_%{index}.%{file_extension}
time_slice_format %Y-%m-%d
# if you want to use ${tag} or %Y/%m/%d/ like syntax in path / s3_object_key_format,
# need to specify tag for ${tag} and time for %Y/%m/%d in <buffer> argument.
<buffer tag,time>
@type file
flush_interval 50
flush_at_shutdown true
path /var/log/fluent/azurestorageappendblob
timekey 5 # 1 hour partition
timekey_use_utc true # use utc
</buffer>
</match>